解析の準備¶
解析の準備では、以下の 4 つの作業を行います。
本解析ドキュメントでは、以下の観測データの解析を参考に HSC pipeline の使い方を紹介していきます。
HSC 生データをデータディレクトリへダウンロード¶
HSC により観測されたデータは STARS(Subaru Telescope Archive System) からダウンロードすることができます。まず自身のユーザーID、パスワードを使って STARS にログインします。 ログインしたら、左上の Search by というタブから Proposal_ID Instrument や Proposal_ID を選択します。
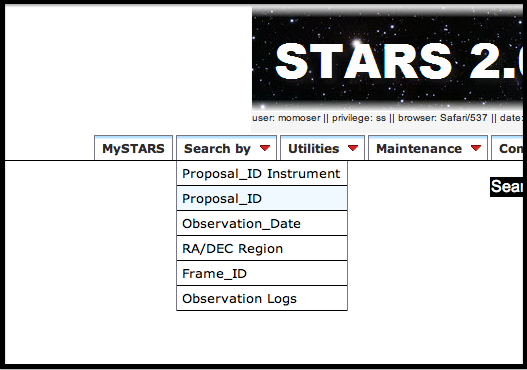
図1:STARS 検索タブ
例えば Proposal_ID を選択した場合、自身のプロポーズ番号を入れて [search] ボタンを押すと 図2 のように検索結果が表示されます。 このプロポーザルIDの全てのデータをダウンロードしたい場合は赤枠で示した [Store query] を押してデータのリクエストを投げましょう。 もし、ある特定のデータをダウンロードしたい場合は 図2 青枠で示したボックスに 12 桁のデータ名を記入すれば、指定したデータのみのリクエストを投げることができます。 データリクエストによる結果はデータ量に応じて数分程度の時間がかかります。気長に待ちましょう。
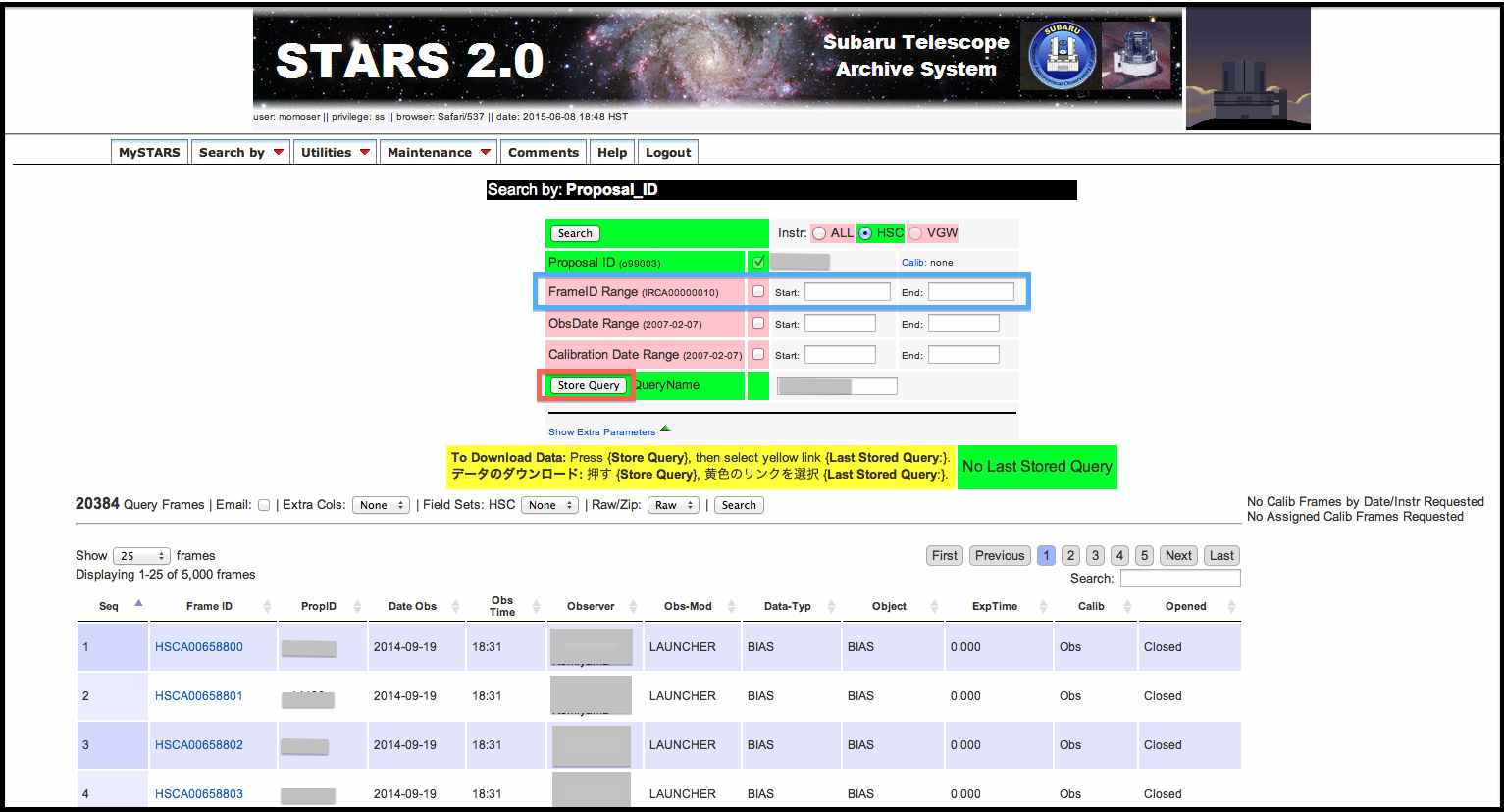
図2:STARS 検索結果
図3 にはデータリクエストによる結果を表示しています。 このページをスクロールしていくと、左下に Wget Input Files というボックスがあります。 この中の DownloadTar にある S2Query.tar 中にデータをダウンロードするための python script が入っています。 そこで S2Query.tar を自身の計算機にダウンロードしてファイルを解凍し、データをダウンロードしてください。
# データディレクトリを作成
mkdir ~/data
cd data
mv ~/Downloads/S2Query.tar .
# S2Query.tar を解凍
tar xvf S2Query.tar
# S2Query.tar を展開すると ~/data 以下に zadmin/ zip/ zvalidate/ というディレクトリが生成される
# リクエストしたデータをダウンロードする python script の実行
# ./zadmin にて下記の通り script を実行しないとダウンロードできないので注意 !!!
./zadmin/unpack.py

図3:STARS Query 結果
生データをダウンロードしたディレクトリ内を ls で見てみると HSCA123456**.fits という名前のデータが見つかると思います。 HSC で取得された生データの名前については HSC で取得される生データ名 のページをご覧ください。
HSC pipeline のセットアップ¶
データのダウンロードが終わったら HSC pipeline のセットアップを行います。HSC pipeline のセットアップはログインする度に必ず行ってください。
cd ~/
# HSC pipeline を呼び出すためのセットアップコマンド
setup-hscpipe
解析用ディレクトリを作成¶
HSC pipeline を用いた解析リポジトリの親となるディレクトリを作成します。 解析の実行 で例示した解析リポジトリは、ここで作成するディレクトリ下に構築されます。 解析用ディレクトリの作成にあたりもう 1 つ重要なことは、 解析用ディレクトリ下に _mapper というファイルを作成することです。 _mapper ファイルは解析で使用するデータがデータベースのどこにあるかを示す指標の役割をしており、 このファイルのあるディレクトリ下に解析用リポジトリが構築されます。
# 解析用ディレクトリ(リポジトリの親ディレクトリ)の作成
mkdir ~/hsc
# _mapper ファイルの作成
echo 'lsst.obs.hsc.HscMapper' > ~/hsc/_mapper
生データに対しレジストリを作成¶
ダウンロードした生データを解析ディレクトリの中に配置し、レジストリを作成します。 使用する HSC pipeline のコマンドは hscIngestImages.py です。
# 生データのあるディレクトリに移動
cd ~/data
# 解析ディレクトリ下にレジストリを作成
hscIngestImages.py ~/hsc ./*.fits --mode=link --create
# 使い方:hscIngestImages.py <解析用ディレクトリ> <fits file 名> --mode=*** --create
#
# オプション:
# --mode :新たにレジストリを作成する際のデータの配置法を指定。move, copy, link, skip がある
# --create :新たにレジストリを作成する際の引数
Warning
HSC pipeline のコマンドでディレクトリを指定する時は、必ず 絶対パス で指定してください!!
hscIngestImages.py が正常に動くと ~/hsc 下に <object name> , DOMEFLAT , DARK 等のデータディレクトリが新たに生成され、その中に生データが配置されているはずです。 また、hscIngestImages.py によって ~/hsc 下に配置された画像の情報は registry.sqlite3 というレジストリに登録されます。 registry.sqlite3 に登録された情報は SQL というデータベース言語を用いて検索することができます。
このドキュメント内では DITH-16H という object の G-band、I-band の解析を参考に HSC pipeline の使い方を紹介していきます。 では、どのような画像が登録されたか見てみることにしましょう。
# レジストリを SQL で込む
sqlite3 ~/hsc/registry.sqlite3
# ヘッダー情報の読み込み
sqlite> .header on
# visit 番号、filter 名、field 名、visit 数を選択
sqlite> SELECT visit, filter, field, count(visit)
...> FROM raw # 生データのレジストリから上記情報を選択
...> GROUP BY visit, filter, field; # visit > filter > field 順に並べて表示
#(ここに 図4 のように検索結果が表示される)
# レジストリの検索終了
sqlite> .q
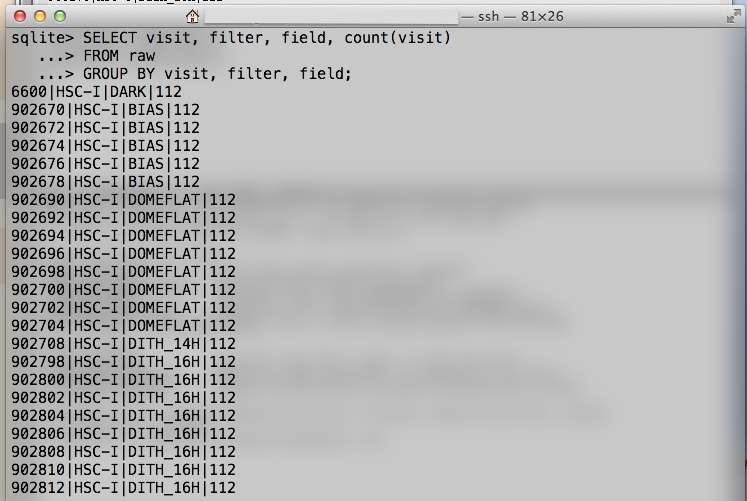
図4 sqlite3 による生データの検索結果
この検索結果から読み取れることは、全ての visit で全ての CCD のデータがある(112個)という点と、各 field で
- DITH_16H (G-band) :visit 番号 903160, 903162, ... , 903188
- DITH_16H (I-band) :visit 番号 902798, 902800, ... , 902870
- BIAS :visit 番号 902670, 902672, ... , 902678
- DARK :visit 番号 006600
- FLAT (G-band) :visit 番号 903036, 903038, ... , 903044
- FLAT (I-band) :visit 番号 902690, 902692, ... , 902704
のデータがあるという点です。以降の解析はこれらの情報を使って行います。
Warning
HSC pipeline の解析は CCD データが 112 個より少ないと、解析が失敗しているにも関わらず pipeline 処理が進んでしまう場合があります。 必ず各 visit で CCD データが 112 個あることを確認 しておきましょう。
最後に sqlite3 を用いた上記以外のレジストリの検索方法を少しご紹介します。 データの情報は table に分類され格納されています。そこで、まず現時点でどのような table があるか調べます。ここではまだ生データしかありませんので、raw と raw_visit の 2 種類しかありません。 この raw の中に各 object, visit, ccd, filter といった様々な情報が格納されています。例では全ての情報を表示させています。 下記の方法で実行した検索結果は 図5 に表示しています。
# 検索結果のカラムの説明を表示させるおまじない
sqlite> .explain on
# table の内容を表示
sqlite> .table
raw raw_visit
# raw という table から全てのヘッダー情報を選択
sqlite> select * from raw
...> group by visit; # visit 順に表示
# 以下、検索結果
#
id taiObs expI poin data visit da frameId filter field pa expTime ccdTemp ccd proposal config autoguider
---- ------------- ---- ---- ---- ------------- -- ------------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ------------ ----------
49 2014-09-19 HSCA00660000 992 DARK 6600 2014-09-19 HSCA00660048 HSC-I DARK 90.347 30.0 -100.594 111 o14422 20140306.cfg 0
...
sqlite> .help # sqlite3 でレジストリを検索する際のヘルプ
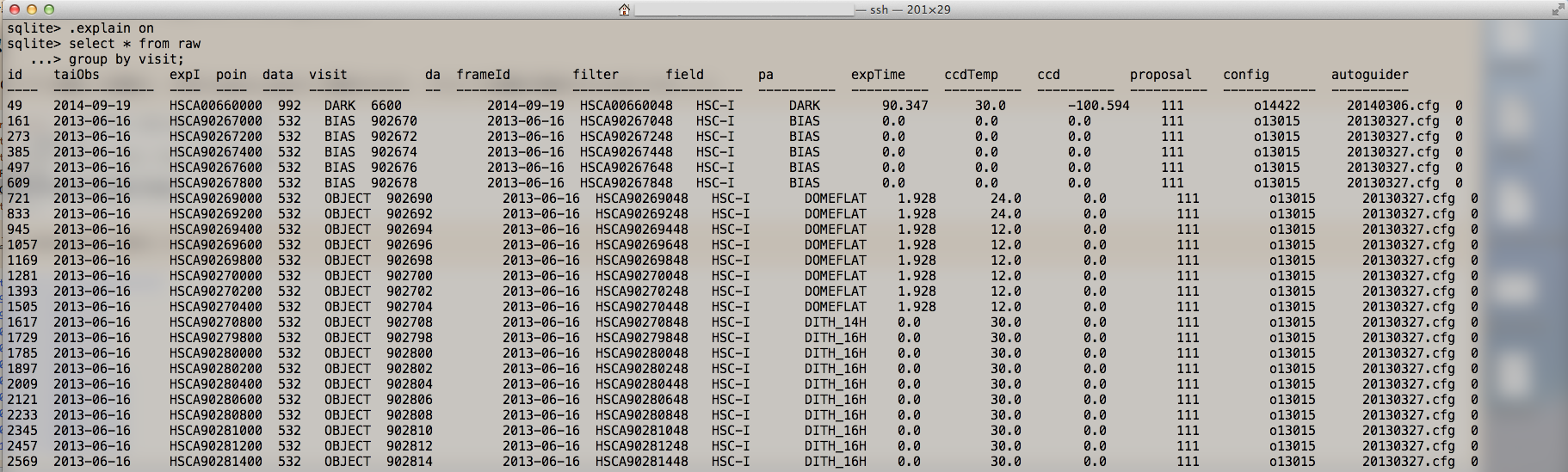
図5 sqlite3 による生データの検索結果その2